In this tutorial you will learn how to implement Generative Adversarial Networks (GANs) using Keras and TensorFlow.
Generative Adversarial Networks were first introduced by Goodfellow et al. in their 2014 paper, Generative Adversarial Networks. These networks can be used to generate synthetic (i.e., fake) images that are perceptually near identical to their ground-truth authentic originals.
In order to generate synthetic images, we make use of two neural networks during training:
- A generator that accepts an input vector of randomly generated noise and produces an output “imitation” image that looks similar, if not identical, to the authentic image
- A discriminator or adversary that attempts to determine if a given image is an “authentic” or “fake”
By training these networks at the same time, one giving feedback to the other, we can learn to generate synthetic images.
Inside this tutorial we’ll be implementing a variation of Radford et al.’s paper, Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks — or more simply, DCGANs.
As we’ll find out, training GANs can be a notoriously hard task, so we’ll implement a number of best practices recommended by both Radford et al. and Francois Chollet (creator of Keras and deep learning scientist at Google).
By the end of this tutorial, you’ll have a fully functioning GAN implementation.
To learn how to implement Generative Adversarial Networks (GANs) with Keras and TensorFlow, just keep reading.
GANs with Keras and TensorFlow
Note: This tutorial is a chapter from my book Deep Learning for Computer Vision with Python. If you enjoyed this post and would like to learn more about deep learning applied to computer vision, be sure to give my book a read — I have no doubt it will take you from deep learning beginner all the way to expert.
In the first part of this tutorial, we’ll discuss what Generative Adversarial Networks are, including how they are different from more “vanilla” network architectures you have seen before for classification and regression.
From there we’ll discuss the general GAN training process, including some guidelines and best practices you should follow when training your own GANs.
Next, we’ll review our directory structure for the project and then implement our GAN architecture using Keras and TensorFlow.
Once our GAN is implemented, we’ll train it on the Fashion MNIST dataset, thereby allowing us to generate fake/synthetic fashion apparel images.
Finally, we’ll wrap up this tutorial on Generative Adversarial Networks with a discussion of our results.
What are Generative Adversarial Networks (GANs)?
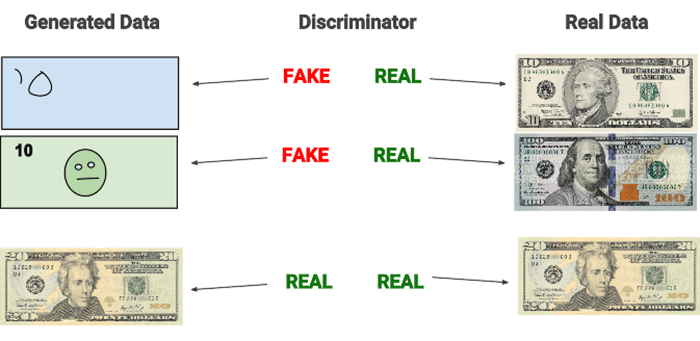
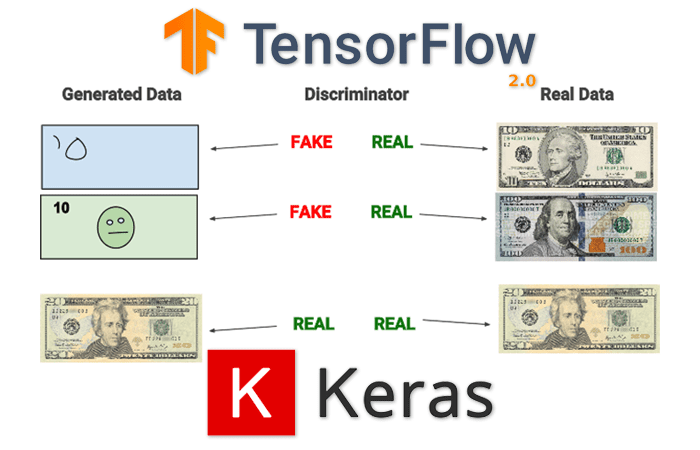
The quintessential explanation of GANs typically involves some variant of two people working in collusion to forge a set of documents, replicate a piece of artwork, or print counterfeit money — the counterfeit money printers is my personal favorite, and the one used by Chollet in his work.
In this example, we have two people:
- Jack, the counterfeit printer (the generator)
- Jason, an employee of the U.S. Treasury (which is responsible for printing money in the United States), who specializes in detecting counterfeit money (the discriminator)
Jack and Jason were childhood friends, both growing up without much money in the rough parts of Boston. After much hard work, Jason was awarded a college scholarship — Jack was not, and over time started to turn toward illegal ventures to make money (in this case, creating counterfeit money).
Jack knew he wasn’t very good at generating counterfeit money, but he felt that with the proper training, he could replicate bills that were passable in circulation.
One day, after a few too many pints at a local pub during the Thanksgiving holiday, Jason let it slip to Jack that he wasn’t happy with his job. He was underpaid. His boss was nasty and spiteful, often yelling and embarrassing Jason in front of other employees. Jason was even thinking of quitting.
Jack saw an opportunity to use Jason’s access at the U.S. Treasury to create an elaborate counterfeit printing scheme. Their conspiracy worked like this:
- Jack, the counterfeit printer, would print fake bills and then mix both the fake bills and real money together, then show them to the expert, Jason.
- Jason would sort through the bills, classifying each bill as “fake” or “authentic,” giving feedback to Jack along the way on how he could improve his counterfeit printing.
At first, Jack is doing a pretty poor job at printing counterfeit money. But over time, with Jason’s guidance, Jack eventually improves to the point where Jason is no longer able to spot the difference between the bills. By the end of this process, both Jack and Jason have stacks of counterfeit money that can fool most people.
The general GAN training procedure
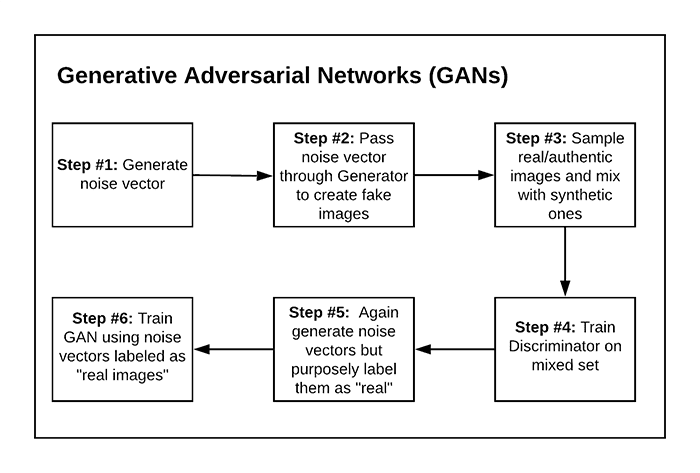
We’ve discussed what GANs are in terms of an analogy, but what is the actual procedure to train them? Most GANs are trained using a six-step process.
To start (Step 1), we randomly generate a vector (i.e., noise). We pass this noise through our generator, which generates an actual image (Step 2). We then sample authentic images from our training set and mix them with our synthetic images (Step 3).
The next step (Step 4) is to train our discriminator using this mixed set. The goal of the discriminator is to correctly label each image as “real” or “fake.”
Next, we’ll once again generate random noise, but this time we’ll purposely label each noise vector as a “real image” (Step 5). We’ll then train the GAN using the noise vectors and “real image” labels even though they are not actual real images (Step 6).
The reason this process works is due to the following:
- We have frozen the weights of the discriminator at this stage, implying that the discriminator is not learning when we update the weights of the generator.
- We’re trying to “fool” the discriminator into being unable to determine which images are real vs. synthetic. The feedback from the discriminator will allow the generator to learn how to produce more authentic images.
If you’re confused with this process, I would continue reading through our implementation covered later in this tutorial — seeing a GAN implemented in Python and then explained makes it easier to understand the process.
Guidelines and best practices when training GANs
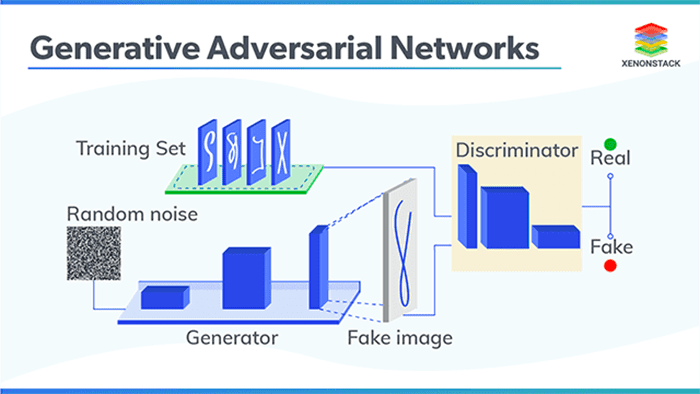
GANs are notoriously hard to train due to an evolving loss landscape. At each iteration of our algorithm we are:
- Generating random images and then training the discriminator to correctly distinguish the two
- Generating additional synthetic images, but this time purposely trying to fool the discriminator
- Updating the weights of the generator based on the feedback of the discriminator, thereby allowing us to generate more authentic images
From this process you’ll notice there are two losses we need to observe: one loss for the discriminator and a second loss for the generator. And since the loss landscape of the generator can be changed based on the feedback from the discriminator, we end up with a dynamic system.
When training GANs, our goal is not to seek a minimum loss value but instead to find some equilibrium between the two (Chollet 2017).
This concept of finding an equilibrium may make sense on paper, but once you try to implement and train your own GANs, you’ll find that this is a nontrivial process.
In their paper, Radford et al. recommend the following architecture guidelines for more stable GANs:
- Replace any pooling layers with strided convolutions (see this tutorial for more information on convolutions and strided convolutions).
- Use batch normalization in both the generator and discriminator.
- Remove fully-connected layers in deeper networks.
- Use ReLU in the generator except for the final layer, which will utilize tanh.
- Use Leaky ReLU in the discriminator.
In his book, Francois Chollet then provides additional recommendations on training GANs:
- Sample random vectors from a normal distribution (i.e., Gaussian distribution) rather than a uniform distribution.
- Add dropout to the discriminator.
- Add noise to the class labels when training the discriminator.
- To reduce checkerboard pixel artifacts in the output image, use a kernel size that is divisible by the stride when utilizing convolution or transposed convolution in both the generator and discriminator.
- If your adversarial loss rises dramatically while your discriminator loss falls to zero, try reducing the learning rate of the discriminator and increasing the dropout of the discriminator.
Keep in mind that these are all just heuristics found to work in a number of situations — we’ll be using some of the techniques suggested by both Radford et al. and Chollet, but not all of them.
It is possible, and even probable, that the techniques listed here will not work on your GANs. Take the time now to set your expectations that you’ll likely be running orders of magnitude more experiments when tuning the hyperparameters of your GANs as compared to more basic classification or regression tasks.
Configuring your development environment to train GANs with Keras and TensorFlow
We’ll be using Keras and TensorFlow to implement and train our GANs.
I recommend you follow either of these two guides to install TensorFlow and Keras on your system:
Either tutorial will help you configure your system with all the necessary software for this blog post in a convenient Python virtual environment.
Having problems configuring your development environment?
All that said, are you:
- Short on time?
- Learning on your employer’s administratively locked system?
- Wanting to skip the hassle of fighting with the command line, package managers, and virtual environments?
- Ready to run the code right now on your Windows, macOS, or Linux system?
Then join PyImageSearch Plus today!
Gain access to Jupyter Notebooks for this tutorial and other PyImageSearch guides that are pre-configured to run on Google Colab’s ecosystem right in your web browser! No installation required.
And best of all, these Jupyter Notebooks will run on Windows, macOS, and Linux!
Project structure
Now that we understand the fundamentals of Generative Adversarial Networks, let’s review our directory structure for the project.
Make sure you use the “Downloads” section of this tutorial to download the source code to our GAN project:
$ tree . --dirsfirst . ├── output │ ├── epoch_0001_output.png │ ├── epoch_0001_step_00000.png │ ├── epoch_0001_step_00025.png ... │ ├── epoch_0050_step_00300.png │ ├── epoch_0050_step_00400.png │ └── epoch_0050_step_00500.png ├── pyimagesearch │ ├── __init__.py │ └── dcgan.py └── dcgan_fashion_mnist.py 3 directories, 516 files
The dcgan.py file inside the pyimagesearch module contains the implementation of our GAN in Keras and TensorFlow.
The dcgan_fashion_mnist.py script will take our GAN implementation and train it on the Fashion MNIST dataset, thereby allowing us to generate “fake” examples of clothing using our GAN.
The output of the GAN after every set number of steps/epochs will be saved to the output directory, allowing us to visually monitor and validate that the GAN is learning how to generate fashion items.
Implementing our “generator” with Keras and TensorFlow
Now that we’ve reviewed our project directory structure, let’s get started implementing our Generative Adversarial Network using Keras and TensorFlow.
Open up the dcgan.py file in our project directory structure, and let’s get started:
# import the necessary packages from tensorflow.keras.models import Sequential from tensorflow.keras.layers import BatchNormalization from tensorflow.keras.layers import Conv2DTranspose from tensorflow.keras.layers import Conv2D from tensorflow.keras.layers import LeakyReLU from tensorflow.keras.layers import Activation from tensorflow.keras.layers import Flatten from tensorflow.keras.layers import Dense from tensorflow.keras.layers import Reshape
Lines 2-10 import our required Python packages. All of these classes should look fairly familiar to you, especially if you’ve read my Keras and TensorFlow tutorials or my book Deep Learning for Computer Vision with Python.
The only exception may be the Conv2DTranspose class. Transposed convolutional layers, sometimes referred to as fractionally-strided convolution or (incorrectly) deconvolution, are used when we need a transform going in the opposite direction of a normal convolution.
The generator of our GAN will accept an N dimensional input vector (i.e., a list of numbers, but a volume like an image) and then transform the N dimensional vector into an output image.
This process implies that we need to reshape and then upscale this vector into a volume as it passes through the network — to accomplish this reshaping and upscaling, we’ll need transposed convolution.
We can thus look at transposed convolution as the method to:
- Accept an input volume from a previous layer in the network
- Produce an output volume that is larger than the input volume
- Maintain a connectivity pattern between the input and output
In essence our transposed convolution layer will reconstruct our target spatial resolution and perform a normal convolution operation, utilizing fancy zero-padding techniques to ensure our output spatial dimensions are met.
To learn more about transposed convolution, take a look at the Convolution arithmetic tutorial in the Theano documentation along with An introduction to different Types of Convolutions in Deep Learning By Paul-Louis Pröve.
Let’s now move into implementing our DCGAN class:
class DCGAN: @staticmethod def build_generator(dim, depth, channels=1, inputDim=100, outputDim=512): # initialize the model along with the input shape to be # "channels last" and the channels dimension itself model = Sequential() inputShape = (dim, dim, depth) chanDim = -1
Here we define the build_generator function inside DCGAN. The build_generator accepts a number of arguments:
dimdepthchannels1for grayscale images and3for RGB images)inputDimoutputDim
The usage of these parameters will become more clear as we define the body of the network in the next code block.
Line 19 defines the inputShape of the volume after we reshape it from the fully-connected layer.
Line 20 sets the channel dimension (chanDim), which we assume to be “channels-last” ordering (the standard channel ordering for TensorFlow).
Below we can find the body of our generator network:
# first set of FC => RELU => BN layers
model.add(Dense(input_dim=inputDim, units=outputDim))
model.add(Activation("relu"))
model.add(BatchNormalization())
# second set of FC => RELU => BN layers, this time preparing
# the number of FC nodes to be reshaped into a volume
model.add(Dense(dim * dim * depth))
model.add(Activation("relu"))
model.add(BatchNormalization())
Lines 23-25 define our first set of FC => RELU => BN layers — applying batch normalization to stabilize GAN training is a guideline from Radford et al. (see the “Guidelines and best practices when training GANs” section above).
Notice how our FC layer will have an input dimension of inputDim (the randomly generated input vector) and then output dimensionality of outputDim. Typically outputDim will be larger than inputDim.
Lines 29-31 apply a second set of FC => RELU => BN layers, but this time we prepare the number of nodes in the FC layer to equal the number of units in inputShape (Line 29). Even though we are still utilizing a flattened representation, we need to ensure the output of this FC layer can be reshaped to our target volume sze (i.e., inputShape).
The actual reshaping takes place in the next code block:
# reshape the output of the previous layer set, upsample +
# apply a transposed convolution, RELU, and BN
model.add(Reshape(inputShape))
model.add(Conv2DTranspose(32, (5, 5), strides=(2, 2),
padding="same"))
model.add(Activation("relu"))
model.add(BatchNormalization(axis=chanDim))
A call to Reshape while supplying the inputShape allows us to create a 3D volume from the fully-connected layer on Line 29. Again, this reshaping is only possible due to the fact that the number of output nodes in the FC layer matches the target inputShape.
We now reach an important guideline when training your own GANs:
- To increase spatial resolution, use a transposed convolution with a stride > 1.
- To create a deeper GAN without increasing spatial resolution, you can use either standard convolution or transposed convolution (but keep the stride equal to 1).
Here, our transposed convolution layer is learning 32 filters, each of which is 5×5, while applying a 2×2 stride — since our stride is > 1, we can increase our spatial resolution.
Let’s apply another transposed convolution:
# apply another upsample and transposed convolution, but
# this time output the TANH activation
model.add(Conv2DTranspose(channels, (5, 5), strides=(2, 2),
padding="same"))
model.add(Activation("tanh"))
# return the generator model
return model
Lines 43 and 44 apply another transposed convolution, again increasing the spatial resolution, but taking care to ensure the number of filters learned is equal to the target number of channels (1 for grayscale and 3 for RGB).
We then apply a tanh activation function per the recommendation of Radford et al. The model is then returned to the calling function on Line 48.
Understanding the “generator” in our GAN
Assuming dim=7, depth=64, channels=1, inputDim=100, and outputDim=512 (as we will use when training our GAN on Fashion MNIST later in this tutorial), I have included the model summary below:
Model: "sequential" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= dense (Dense) (None, 512) 51712 _________________________________________________________________ activation (Activation) (None, 512) 0 _________________________________________________________________ batch_normalization (BatchNo (None, 512) 2048 _________________________________________________________________ dense_1 (Dense) (None, 3136) 1608768 _________________________________________________________________ activation_1 (Activation) (None, 3136) 0 _________________________________________________________________ batch_normalization_1 (Batch (None, 3136) 12544 _________________________________________________________________ reshape (Reshape) (None, 7, 7, 64) 0 _________________________________________________________________ conv2d_transpose (Conv2DTran (None, 14, 14, 32) 51232 _________________________________________________________________ activation_2 (Activation) (None, 14, 14, 32) 0 _________________________________________________________________ batch_normalization_2 (Batch (None, 14, 14, 32) 128 _________________________________________________________________ conv2d_transpose_1 (Conv2DTr (None, 28, 28, 1) 801 _________________________________________________________________ activation_3 (Activation) (None, 28, 28, 1) 0 =================================================================
Let’s break down what’s going on here.
First, our model will accept an input vector that is 100-d, then transform it to a 512-d vector via an FC layer.
We then add a second FC layer, this one with 7x7x64 = 3,136 nodes. We reshape these 3,136 nodes into a 3D volume with shape 7×7 = 64 — this reshaping is only possible since our previous FC layer matches the number of nodes in the reshaped volume.
Applying a transposed convolution with a 2×2 stride increases our spatial dimensions from 7×7 to 14×14.
A second transposed convolution (again, with a stride of 2×2) increases our spatial dimension resolution from 14×14 to 28×18 with a single channel, which is the exact dimensions of our input images in the Fashion MNIST dataset.
When implementing your own GANs, make sure the spatial dimensions of the output volume match the spatial dimensions of your input images. Use transposed convolution to increase the spatial dimensions of the volumes in the generator. I also recommend using model.summary() often to help you debug the spatial dimensions.
Implementing our “discriminator” with Keras and TensorFlow
The discriminator model is substantially more simplistic, similar to basic CNN classification architectures you may have read in my book or elsewhere on the PyImageSearch blog.
Keep in mind that while the generator is intended to create synthetic images, the discriminator is used to classify whether any given input image is real or fake.
Continuing our implementation of the DCGAN class in dcgan.py, let’s take a look at the discriminator now:
@staticmethod
def build_discriminator(width, height, depth, alpha=0.2):
# initialize the model along with the input shape to be
# "channels last"
model = Sequential()
inputShape = (height, width, depth)
# first set of CONV => RELU layers
model.add(Conv2D(32, (5, 5), padding="same", strides=(2, 2),
input_shape=inputShape))
model.add(LeakyReLU(alpha=alpha))
# second set of CONV => RELU layers
model.add(Conv2D(64, (5, 5), padding="same", strides=(2, 2)))
model.add(LeakyReLU(alpha=alpha))
# first (and only) set of FC => RELU layers
model.add(Flatten())
model.add(Dense(512))
model.add(LeakyReLU(alpha=alpha))
# sigmoid layer outputting a single value
model.add(Dense(1))
model.add(Activation("sigmoid"))
# return the discriminator model
return model
As we can see, this network is simple and straightforward. We first learn 32, 5×5 filters, followed by a second CONV layer, this one learning a total of 64, 5×5 filters. We only have a single FC layer here, this one with 512 nodes.
All activation layers utilize a Leaky ReLU activation to stabilize training, except for the final activation function which is sigmoid. We use a sigmoid here to capture the probability of whether the input image is real or synthetic.
Implementing our GAN training script
Now that we’ve implemented our DCGAN architecture, let’s train it on the Fashion MNIST dataset to generate fake apparel items. By the end of the training process, we will be unable to identify real images from synthetic ones.
Open up the dcgan_fashion_mnist.py file in our project directory structure, and let’s get to work:
# import the necessary packages from pyimagesearch.dcgan import DCGAN from tensorflow.keras.models import Model from tensorflow.keras.layers import Input from tensorflow.keras.optimizers import Adam from tensorflow.keras.datasets import fashion_mnist from sklearn.utils import shuffle from imutils import build_montages import numpy as np import argparse import cv2 import os
We start off by importing our required Python packages.
Notice that we’re importing DCGAN, which is our implementation of the GAN architecture from the previous section (Line 2).
We also import the build_montages function (Line 8). This is a convenience function that will enable us to easily build a montage of generated images and then display them to our screen as a single image. You can read more about building montages in my tutorial Montages with OpenCV.
Let’s move to parsing our command line arguments:
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-o", "--output", required=True,
help="path to output directory")
ap.add_argument("-e", "--epochs", type=int, default=50,
help="# epochs to train for")
ap.add_argument("-b", "--batch-size", type=int, default=128,
help="batch size for training")
args = vars(ap.parse_args())
We require only a single command line argument for this script, --output, which is the path to the output directory where we’ll store montages of generated images (thereby allowing us to visualize the GAN training process).
We can also (optionally) supply --epochs, the total number of epochs to train for, and --batch-size, used to control the batch size when training.
Let’s now take care of a few important initializations:
# store the epochs and batch size in convenience variables, then # initialize our learning rate NUM_EPOCHS = args["epochs"] BATCH_SIZE = args["batch_size"] INIT_LR = 2e-4
We store both the number of epochs and batch size in convenience variables on Lines 26 and 27.
We also initialize our initial learning rate (INIT_LR) on Line 28. This value was empirically tuned through a number of experiments and trial and error. If you choose to apply this GAN implementation to your own dataset, you may need to tune this learning rate.
We can now load the Fashion MNIST dataset from disk:
# load the Fashion MNIST dataset and stack the training and testing
# data points so we have additional training data
print("[INFO] loading MNIST dataset...")
((trainX, _), (testX, _)) = fashion_mnist.load_data()
trainImages = np.concatenate([trainX, testX])
# add in an extra dimension for the channel and scale the images
# into the range [-1, 1] (which is the range of the tanh
# function)
trainImages = np.expand_dims(trainImages, axis=-1)
trainImages = (trainImages.astype("float") - 127.5) / 127.5
Line 33 loads the Fashion MNIST dataset from disk. We ignore class labels here, since we do not need them — we are only interested in the actual pixel data.
Furthermore, there is no concept of a “test set” for GANs. Our goal when training a GAN isn’t minimal loss or high accuracy. Instead, we seek an equilibrium between the generator and the discriminator.
To help us obtain this equilibrium, we combine both the training and testing images (Line 34) to give us additional training data.
Lines 39 and 40 prepare our data for training by scaling the pixel intensities to the range [0, 1], the output range of the tanh activation function.
Let’s now initialize our generator and discriminator:
# build the generator
print("[INFO] building generator...")
gen = DCGAN.build_generator(7, 64, channels=1)
# build the discriminator
print("[INFO] building discriminator...")
disc = DCGAN.build_discriminator(28, 28, 1)
discOpt = Adam(lr=INIT_LR, beta_1=0.5, decay=INIT_LR / NUM_EPOCHS)
disc.compile(loss="binary_crossentropy", optimizer=discOpt)
Line 44 initializes the generator that will transform the input random vector to a volume of shape 7x7x64-channel map.
Lines 48-50 build the discriminator and then compile it using the Adam optimizer with binary cross-entropy loss.
Keep in mind that we are using binary cross-entropy here, as our discriminator has a sigmoid activation function that will return a probability indicating whether the input image is real vs. fake. Since there are only two “class labels” (real vs. synthetic), we use binary cross-entropy.
The learning rate and beta value for the Adam optimizer were experimentally tuned. I’ve found that a lower learning rate and beta value for the Adam optimizer improves GAN training on the Fashion MNIST dataset. Applying learning rate decay helps stabilize training as well.
Given both the generator and discriminator, we can build our GAN:
# build the adversarial model by first setting the discriminator to
# *not* be trainable, then combine the generator and discriminator
# together
print("[INFO] building GAN...")
disc.trainable = False
ganInput = Input(shape=(100,))
ganOutput = disc(gen(ganInput))
gan = Model(ganInput, ganOutput)
# compile the GAN
ganOpt = Adam(lr=INIT_LR, beta_1=0.5, decay=INIT_LR / NUM_EPOCHS)
gan.compile(loss="binary_crossentropy", optimizer=discOpt)
The actual GAN consists of both the generator and the discriminator; however, we first need to freeze the discriminator weights (Line 56) before we combine the models to form our Generative Adversarial Network (Lines 57-59).
Here we can see that the input to the gan will take a random vector that is 100-d. This value will be passed through the generator first, the output of which will go to the discriminator — we call this “model composition,” similar to “function composition” we learned about back in algebra class.
The discriminator weights are frozen at this point so the feedback from the discriminator will enable the generator to learn how to generate better synthetic images.
Lines 62 and 63 compile the gan. I again use the Adam optimizer with the same hyperparameters as the optimizer for the discriminator — this process worked for the purposes of these experiments, but you may need to tune these values on your own datasets and models.
Additionally, I’ve often found that setting the learning rate of the GAN to be half that of the discriminator is often a good starting point.
Throughout the training process we’ll want to see how our GAN evolves to construct synthetic images from random noise. To accomplish this task, we’ll need to generate some benchmark random noise used to visualize the training process:
# randomly generate some benchmark noise so we can consistently
# visualize how the generative modeling is learning
print("[INFO] starting training...")
benchmarkNoise = np.random.uniform(-1, 1, size=(256, 100))
# loop over the epochs
for epoch in range(0, NUM_EPOCHS):
# show epoch information and compute the number of batches per
# epoch
print("[INFO] starting epoch {} of {}...".format(epoch + 1,
NUM_EPOCHS))
batchesPerEpoch = int(trainImages.shape[0] / BATCH_SIZE)
# loop over the batches
for i in range(0, batchesPerEpoch):
# initialize an (empty) output path
p = None
# select the next batch of images, then randomly generate
# noise for the generator to predict on
imageBatch = trainImages[i * BATCH_SIZE:(i + 1) * BATCH_SIZE]
noise = np.random.uniform(-1, 1, size=(BATCH_SIZE, 100))
Line 68 generates our benchmarkNoise. Notice that the benchmarkNoise is generated from a uniform distribution in the range [-1, 1], the same range as our tanh activation function. Line 68 indicates that we’ll be generating 256 synthetic images, where each input starts as a 100-d vector.
Starting on Line 71 we loop over our desired number of epochs. Line 76 computes the number of batches per epoch by dividing the number of training images by the supplied batch size.
We then loop over each batch on Line 79.
Line 85 subsequently extracts the next imageBatch, while Line 86 generates the random noise that we’ll be passing through the generator.
Given the noise vector, we can use the generator to generate synthetic images:
# generate images using the noise + generator model genImages = gen.predict(noise, verbose=0) # concatenate the *actual* images and the *generated* images, # construct class labels for the discriminator, and shuffle # the data X = np.concatenate((imageBatch, genImages)) y = ([1] * BATCH_SIZE) + ([0] * BATCH_SIZE) y = np.reshape(y, (-1,)) (X, y) = shuffle(X, y) # train the discriminator on the data discLoss = disc.train_on_batch(X, y)
Line 89 takes our input noise and then generates synthetic apparel images (genImages).
Given our generated images, we need to train the discriminator to recognize the difference between real and synthetic images.
To accomplish this task, Line 94 concatenates the current imageBatch and the synthetic genImages together.
We then need to build our class labels on Line 95 — each real image will have a class label of 1, while every fake image will be labeled 0.
The concatenated training data is then jointly shuffled on Line 97 so our real and fake images do not sequentially follow each other one-by-one (which would cause problems during our gradient update phase).
Additionally, I have found this shuffling process improves the stability of discriminator training.
Line 100 trains the discriminator on the current (shuffled) batch.
The final step in our training process is to train the gan itself:
# let's now train our generator via the adversarial model by # (1) generating random noise and (2) training the generator # with the discriminator weights frozen noise = np.random.uniform(-1, 1, (BATCH_SIZE, 100)) fakeLabels = [1] * BATCH_SIZE fakeLabels = np.reshape(fakeLabels, (-1,)) ganLoss = gan.train_on_batch(noise, fakeLabels)
We first generate a total of BATCH_SIZE random vectors. However, unlike in our previous code block, where we were nice enough to tell our discriminator what is real vs. fake, we’re now going to attempt to trick the discriminator by labeling the random noise as real images.
The feedback from the discriminator enables us to actually train the generator (keeping in mind that the discriminator weights are frozen for this operation).
Not only is looking at the loss values important when training a GAN, but you also need to examine the output of the gan on your benchmarkNoise:
# check to see if this is the end of an epoch, and if so,
# initialize the output path
if i == batchesPerEpoch - 1:
p = [args["output"], "epoch_{}_output.png".format(
str(epoch + 1).zfill(4))]
# otherwise, check to see if we should visualize the current
# batch for the epoch
else:
# create more visualizations early in the training
# process
if epoch < 10 and i % 25 == 0:
p = [args["output"], "epoch_{}_step_{}.png".format(
str(epoch + 1).zfill(4), str(i).zfill(5))]
# visualizations later in the training process are less
# interesting
elif epoch >= 10 and i % 100 == 0:
p = [args["output"], "epoch_{}_step_{}.png".format(
str(epoch + 1).zfill(4), str(i).zfill(5))]
If we have reached the end of the epoch, we’ll build the path, p, to our output visualization (Lines 112-114).
Otherwise, I find it helpful to visually inspect the output of our GAN with more frequency in earlier steps rather than later ones (Lines 118-129).
The output visualization will be totally random salt and pepper noise at the beginning but should quickly start to develop characteristics of the input data. These characteristics may not look real, but the evolving attributes will demonstrate to you that the network is actually learning.
If your output visualizations are still salt and pepper noise after 5-10 epochs, it may be a sign that you need to tune your hyperparameters, potentially including the model architecture definition itself.
Our final code block handles writing the synthetic image visualization to disk:
# check to see if we should visualize the output of the
# generator model on our benchmark data
if p is not None:
# show loss information
print("[INFO] Step {}_{}: discriminator_loss={:.6f}, "
"adversarial_loss={:.6f}".format(epoch + 1, i,
discLoss, ganLoss))
# make predictions on the benchmark noise, scale it back
# to the range [0, 255], and generate the montage
images = gen.predict(benchmarkNoise)
images = ((images * 127.5) + 127.5).astype("uint8")
images = np.repeat(images, 3, axis=-1)
vis = build_montages(images, (28, 28), (16, 16))[0]
# write the visualization to disk
p = os.path.sep.join(p)
cv2.imwrite(p, vis)
Line 141 uses our generator to generate images from our benchmarkNoise. We then scale our image data back from the range [-1, 1] (the boundaries of the tanh activation function) to the range [0, 255] (Line 142).
Since we are generating single-channel images, we repeat the grayscale representation of the image three times to construct a 3-channel RGB image (Line 143).
The build_montages function generates a 16×16 grid, with a 28×28 image in each vector. The montage is then written to disk on Line 148.
Training our GAN with Keras and TensorFlow
To train our GAN on the Fashion MNIST dataset, make sure you use the “Downloads” section of this tutorial to download the source code.
From there, open up a terminal, and execute the following command:
$ python dcgan_fashion_mnist.py --output output [INFO] loading MNIST dataset... [INFO] building generator... [INFO] building discriminator... [INFO] building GAN... [INFO] starting training... [INFO] starting epoch 1 of 50... [INFO] Step 1_0: discriminator_loss=0.683195, adversarial_loss=0.577937 [INFO] Step 1_25: discriminator_loss=0.091885, adversarial_loss=0.007404 [INFO] Step 1_50: discriminator_loss=0.000986, adversarial_loss=0.000562 ... [INFO] starting epoch 50 of 50... [INFO] Step 50_0: discriminator_loss=0.472731, adversarial_loss=1.194858 [INFO] Step 50_100: discriminator_loss=0.526521, adversarial_loss=1.816754 [INFO] Step 50_200: discriminator_loss=0.500521, adversarial_loss=1.561429 [INFO] Step 50_300: discriminator_loss=0.495300, adversarial_loss=0.963850 [INFO] Step 50_400: discriminator_loss=0.512699, adversarial_loss=0.858868 [INFO] Step 50_500: discriminator_loss=0.493293, adversarial_loss=0.963694 [INFO] Step 50_545: discriminator_loss=0.455144, adversarial_loss=1.128864

Figure 5 shows our random noise vectors (i.e., benchmarkNoise during different moments of training):
- The top-left contains 256 (in an 8×8 grid) of our initial random noise vectors before even starting to train the GAN. We can clearly see there is no pattern in this noise. No fashion items have been learned by the GAN.
- However, by the end of the second epoch (top-right), apparel-like structures are starting to appear.
- By the end of the fifth epoch (bottom-left), the fashion items are significantly more clear.
- And by the time we reach the end of the 50th epoch (bottom-right), our fashion items look authentic.
Again, it’s important to understand that these fashion items are generated from random noise input vectors — they are totally synthetic images!
What’s next?

As stated at the beginning of this tutorial, the majority of this blog post comes from my book, Deep Learning for Computer Vision with Python (DL4CV).
If you have not yet had the opportunity to join the DL4CV course, I hope you enjoyed your sneak preview! Not only are the fundamentals of neural networks reviewed, covered, and practiced throughout the DL4CV course, but so are more complex models and architectures, including GANs, super resolution, object detection (Faster R-CNN, SSDs, RetinaNet) and instance segmentation (Mask R-CNN).
Whether you are a professional, practitioner, or hobbyist – I crafted my Deep Learning for Computer Vision with Python book so that it perfectly blends theory with code implementation, ensuring you can master:
- Deep learning fundamentals and theory without unnecessary mathematical fluff. I present the basic equations and back them up with code walkthroughs that you can implement and easily understand. You don’t need a degree in advanced mathematics to understand this book.
- How to implement your own custom neural network architectures. Not only will you learn how to implement state-of-the-art architectures, including ResNet, SqueezeNet, etc., but you’ll also learn how to create your own custom CNNs.
- How to train CNNs on your own datasets. Most deep learning tutorials don’t teach you how to work with your own custom datasets. Mine do. You’ll be training CNNs on your own datasets in no time.
- Object detection (Faster R-CNNs, Single Shot Detectors, and RetinaNet) and instance segmentation (Mask R-CNN). Use these chapters to create your own custom object detectors and segmentation networks.
You’ll also find answers and proven code recipes to:
- Create and prepare your own custom image datasets for image classification, object detection, and segmentation
- Work through hands-on tutorials (with lots of code) that not only show you the algorithms behind deep learning for computer vision but their implementations as well
- Put my tips, suggestions, and best practices into action, ensuring you maximize the accuracy of your models
Beginners and experts alike tend to resonate with my no-nonsense teaching style and high-quality content.
If you’re on the fence about taking the next step in your computer vision, deep learning, and artificial intelligence education, be sure to read my Student Success Stories. My readers have gone on to excel in their careers — you can too!
If you’re ready to begin, purchase your copy here today. And if you aren’t convinced yet, I’d be happy to send you the full table of contents + sample chapters — simply click here. You can also browse my library of other book and course offerings.
Summary
In this tutorial we discussed Generative Adversarial Networks (GANs). We learned that GANs actually consist of two networks:
- A generator that is responsible for generating fake images
- A discriminator that tries to spot the synthetic images from the authentic ones
By training both of these networks at the same time, we can learn to generate very realistic output images.
We then implemented Deep Convolutional Adversarial Networks (DCGANS), a variation of Goodfellow et al.’s original GAN implementation.
Using our DCGAN implementation, we trained both the generator and discriminator on the Fashion MNIST dataset, resulting in output images of fashion items that:
- Are not part of the training set and are complete synthetic
- Look nearly identical to and indistinguishable from any image in the Fashion MNIST dataset
The problem is that training GANs can be extremely challenging, more so than any other architecture or method we have discussed on the PyImageSearch blog.
The reason GANs are notoriously hard to train is due to the evolving loss landscape — with every step, our loss landscape changes slightly and is thus ever-evolving.
The evolving loss landscape is in stark contrast to other classification or regression tasks where the loss landscape is “fixed” and nonmoving.
When training your own GANs, you’ll undoubtedly have to carefully tune your model architecture and associated hyperparameters — be sure to refer to the “Guidelines and best practices when training GANs” section at the top of this tutorial to help you tune your hyperparameters and run your own GAN experiments.
To download the source code to this post (and be notified when future tutorials are published here on PyImageSearch), simply enter your email address in the form below!

Download the Source Code and FREE 17-page Resource Guide
Enter your email address below to get a .zip of the code and a FREE 17-page Resource Guide on Computer Vision, OpenCV, and Deep Learning. Inside you'll find my hand-picked tutorials, books, courses, and libraries to help you master CV and DL!
The post GANs with Keras and TensorFlow appeared first on PyImageSearch.





































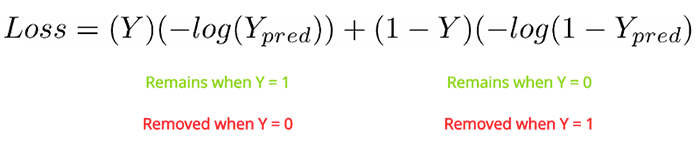
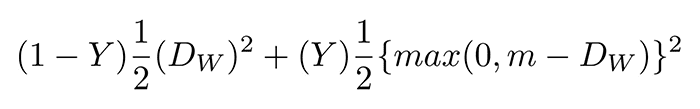
 value is our label. It will be
value is our label. It will be  if the image pairs are of the same class, and it will be
if the image pairs are of the same class, and it will be  if the image pairs are of a different class.
if the image pairs are of a different class. variable is the Euclidean distance between the outputs of the sister network embeddings.
variable is the Euclidean distance between the outputs of the sister network embeddings. , minus the distance.
, minus the distance.















































 . We’ll use
. We’ll use  can be defined by constructing a matrix, M, in the form:
can be defined by constructing a matrix, M, in the form:

 \times c_{x} - \beta \times c_{y} \\-\beta & \alpha & \beta \times c_{x} + (1 - \alpha) \times c_{y}\end{bmatrix}")
 and
and  and
and  and
and  are the respective (x, y)-coordinates around which the rotation is performed.
are the respective (x, y)-coordinates around which the rotation is performed.




